Introduction
In 2021, Joseph M. Peysin submitted a doctoral dissertation to Columbia University titled Descriptive and Experimental Analyses of In-person and Remote Instruction, as part of a Ph.D. in Applied Behavior Analysis (ABA). The study took place during the COVID-19 pandemic, when schools closed and most instruction shifted online. While many educational services paused or adapted, ABA programs continued, moving their teaching onto screens.
The study is situated within a specific model of ABA schooling known as CABAS (Comprehensive Application of Behavior Analysis to Schooling). In this system, instruction is highly structured and measured in small units called “learn units,” where each interaction between teacher and child is tracked and evaluated. Peysin asks whether this system, designed for tightly controlled classroom environments, can be delivered remotely without losing its effectiveness. He proposes to test this by keeping the instructional procedure the same while changing only the setting from classroom to screen. This is presented as a gap in the literature, as CABAS depends on direct interaction, supervision, and precise timing. The study is positioned as a way to determine whether the system can be extended beyond the classroom while maintaining its structure and outcomes.
The Children
Six preschool-aged boys participated in the first experiment of the study. Their names reported in the dissertation are Dente, Jales, David, Clement, Nat, and Mike. Each child was between three and four years old. They were classified as ‘preschoolers with disabilities’ and already enrolled in an intensive Applied Behavior Analysis (ABA) classroom.
The children were further grouped based on prior assessments of language and learning ability. The study organized children according to “verbal behavior development.” This included categories such as “verbal behavior cusps”, defined as basic skills like copying actions or following instructions, or “naming capability“, defined as the child can both understand words and say them. These classifications were used to sort children by their readiness to acquire new targets within the instructional procedure.
In the experiment, an adult called the child’s name and presented a picture, and then asked, “What is this?” Examples used by Peysin were sloth, lynx, hedgehog, meerkat, condor, breadfruit, and cashew.
Table 1 showing the instructional targets used in teaching sessions, including items that may not be familiar to all three-year-old children.
| Category | Items |
| Animals | Sloth, Lynx, Condor, Hedgehog, Meerkat, Yak, Mink, Pug, Mole |
| Foods / Edibles | Ham, Salmon, Mint, Thai, Tea, Ribs, Breadfruit, Fig, Yam, Cashew, Ginger, Honey |
| Sports / Structured Activities | Soccer, Tennis, Hockey, Golf, Skiing, Skating |
| Actions / Verbs | Writing, Climbing, Play, Tying, Crawling, Shopping, Cleaning, Holding, Pushing, Shouting, Bouncing, Jump, Camping |
| Objects / Tools | Scissor, Pen, Marker, Eraser, Ax, Hydrant, Chalkboard, Branch, Wok, Brush, Fountain, Nail, Radio, Wrench |
| Places / Misc Nouns | Cubby, Pad |
| States / Feelings | Tired, Sad, Hot, Bored, Hungry, Surprised, Relaxed |
| Body / Physical States | Coughing |
| Other / Abstract | Where, Three, My |
Next, if the child answered correctly, the adult gave praise or a reward. If the child did not answer within a few seconds, or answered incorrectly, the adult immediately modeled the correct answer and asked again.
This repeated up to seven times. The same picture, or variations of it, appeared again and again until the child gave the correct answer seven times in a row. At that point, the program recorded the skill as “mastered” and moved on to a new item.
For one child, Nat, the task included reading sight words. The word appeared on a screen in different fonts and colors. The question and consequences stayed the same. Correct responses produced reinforcement. Incorrect responses produced correction and repetition.

AI-generated image of six preschool-aged boys in ABA experimentation comparing in-person and remote learning, with the same instructional sequence delivered across settings.
Remote vs In-Person instruction
Peysin designed the experiment to alternate between in-person and remote instruction over a two-week period, with one week in each setting. Instruction was presented on a screen in both settings.
In the classroom experiment, the ABA schoolteacher sat across from the child and delivered instruction directly. The materials appeared on a screen, but the interaction was physical. Token rewards were physical. Reinforcement was immediate. Correction occurred in real time.
In the remote experiment, the ABA schoolteacher delivered the same intervention on Zoom. In the child’s home, a caregiver was required to remain present throughout the session. The caregiver was instructed to maintain attention, redirect behavior, deliver reinforcement, and assist with prompting.
The researcher did not record how often the caregiver intervened, how prompts were delivered, or how reinforcement varied across homes. Differences in caregiver participation were not included as variables. Outcomes of this experiment were discussed based on instructional delivery. The contribution of the caregiver remained unmeasured.

AI-generated image showing in-person and remote ABA instruction following the same sequence of question, response, and reinforcement. The difference is in delivery: direct teacher interaction in the classroom and caregiver-mediated instruction through a screen at home.
What Counts as Learning
The study defined learning as the point at which correct responding stabilized under repeated instruction. The study did not assess whether the child understood the word or could use it outside the teaching context. Instead, it tracked how many trials were required before the child produced correct responses for a fixed learning unit. Additionally, the experimenter logged how quickly those trials were delivered, and how many “correct responses” (targets) were met over time.
The child was never asked “what is this” and released from the experiment. Rather, the study was designed to ask repeatedly until he couldn’t get it wrong. Correct answers only counted if they occurred without error. Two correct responses followed by one mistake returned the child to the beginning of the sequence. The question continued until seven correct answers were produced in a row.
Errors were treated as responses to be reduced through correction and repetition. They were not analyzed as indicators of communication or understanding. The procedure treats errors as events to be corrected through repetition until they no longer occur. The definition of mastery does not include how responses are produced. When the child produced seven correct responses in a row, the system recorded it as mastery. This is what the study called learning, and this definition of learning reflects the study’s operational criteria for evidence.
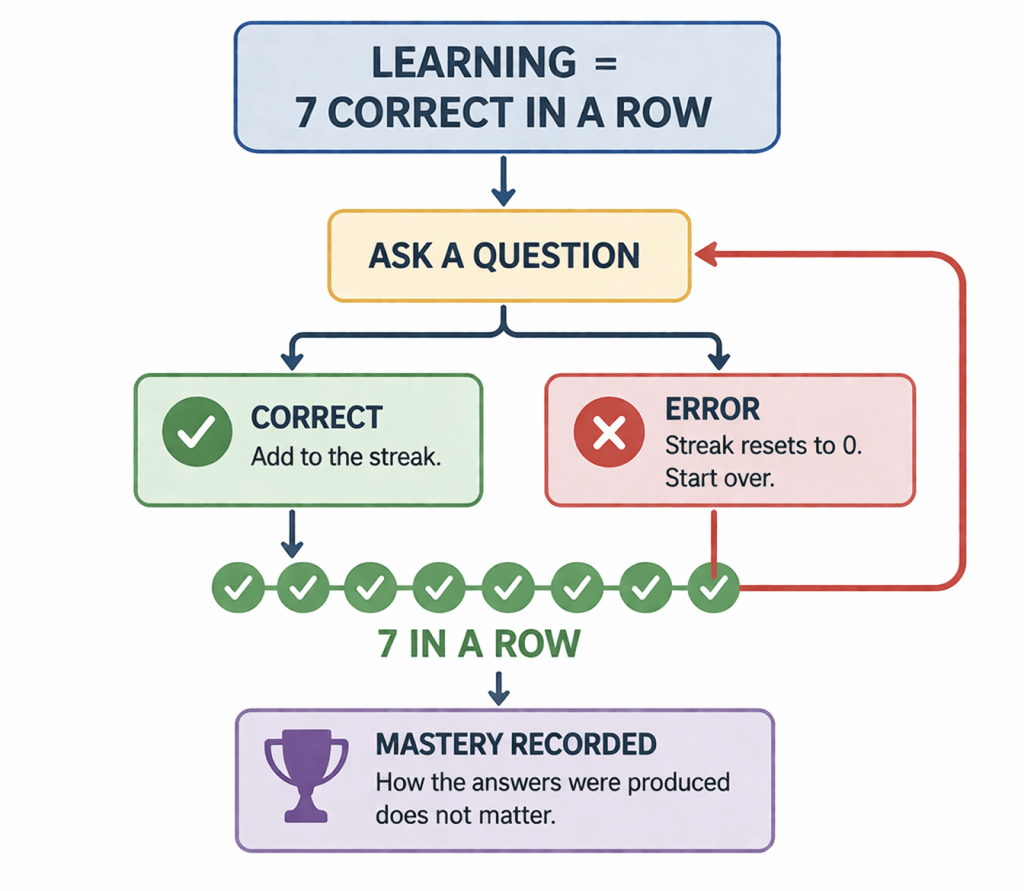
Learning was defined as reaching seven correct responses in a row. Each error reseted the sequence. The process continued until mistakes no longer occurred.
From Individual Sessions to System-Level Measurement
After the experiment examined six children across alternating in-person and remote conditions, the analysis moved to a larger system. Data were drawn from more than one hundred children enrolled in the ABA schools “CABAS” (Comprehensive Application of Behavior Analysis to Schooling) program. In this way, the comparison could be drawn from individual performance to schoolwide program outcomes.
A fully in-person model from the previous 5 years was compared to the hybrid model that included remote instruction. Measures included the number of instructional trials delivered, the rate of “learning”, procedural fidelity, and cost.
Results varied across participants. Some children reached “mastery” faster in person. Others showed comparable performance across conditions. In some comparisons, performance was more efficient in the remote setting. No consistent pattern favored one condition across all participants. Differences occurred within individuals.
Followup assessments that checked whether the children still remembered “what is this”, showed little difference in mastery rates, between remote and in person trials. Rather, mastery criteria were basically the same, regardless of the setting. Peysin concluded that remote instruction produced outcomes comparable to in-person instruction when procedures were controlled.
This conclusion depended on limiting what was allowed to vary. The number of trials were fixed. Materials were matched. The sequence of instruction did not change. The definition of success remained the same. The same teacher delivered both conditions. The procedure was predetermined.
The study did not examine how children experienced instruction across environments, or how attention, motivation, or interaction shifted between classroom and home. It measured whether the procedure produced the same outputs when delivered in a different setting. Only one variable was formally changed. The teacher was either physically present or appeared through a screen. This design isolates modality. It does not assess comprehension or use outside the procedure.
The six children were compared to the other ABA school children, to see if mastery is different in person or remote. Based on the five years of program review containing data of more than 100 students, fully in-person instruction produced more mastered objectives than the hybrid model. Further, Peysin conducted “a cost analysis to determine how much the transition to remote provision of instruction costs stakeholders.” He found that “the dollar cost per each learning outcome was nearly double in the hybrid model compared to the fully in-person model”.
The study treats remote instruction as more expensive because it produces fewer counted units of behavior per dollar. At the same time, it excludes the largest new cost introduced by remote instruction: the transfer of instructional labor to parents. So the conclusion “remote is less cost-effective” is based on reduced output, not on a complete accounting of where the work actually went.
Peysin’s cost analysis defines “cost to stakeholders” as dollars spent per unit of instruction, yet the calculation only includes staff time and school-based resources while excluding the labor that shifts into the home during remote sessions. In the hybrid model, children completed fewer learning trials and mastered fewer targets, which mathematically increased the cost per outcome, but the structure of the analysis treats this as inefficiency rather than redistribution of work.
The caregiver is required to sit through sessions, manage behavior, deliver reinforcers, and sustain the instructional process without being counted in the cost model. This creates a situation where institutional costs appear to rise while unpaid caregiver labor becomes invisible. For a parent reading this, the concern is not simply that remote instruction is “less efficient,” but that the system depends on their time, attention, and compliance to function, while formally assigning that burden no economic or analytic value. Peysin argues that “comparing the funds allocated per student to receive educational services and the instructional outcomes for a school offering remote instruction compared to in-person instruction can be helpful in providing the relevant stakeholders a dollar value in costs of school closures” in the event that the school has an investment in immediate student outcomes.
Ethics, Design, and System Function
Experiments conducted on human children must pass a robust application for a university’s Institutional Review Board (IRB). This study was conducted within existing educational services, not a medical or health clinic. The IRB determined the research to be a minimal-risk classification. This is because instruction was treated as routine, data collection was treated as observation, and the project was framed as a comparison of delivery formats rather than as an intervention. As such, behaviorism language was omitted, and the project description directed attention to procedural compliance and system implementation. The IRB review classified the study as minimal risk based on its framing as routine instruction. Under this classification, the review focused on procedural compliance and did not require assessment of how the procedure was experienced by the child.
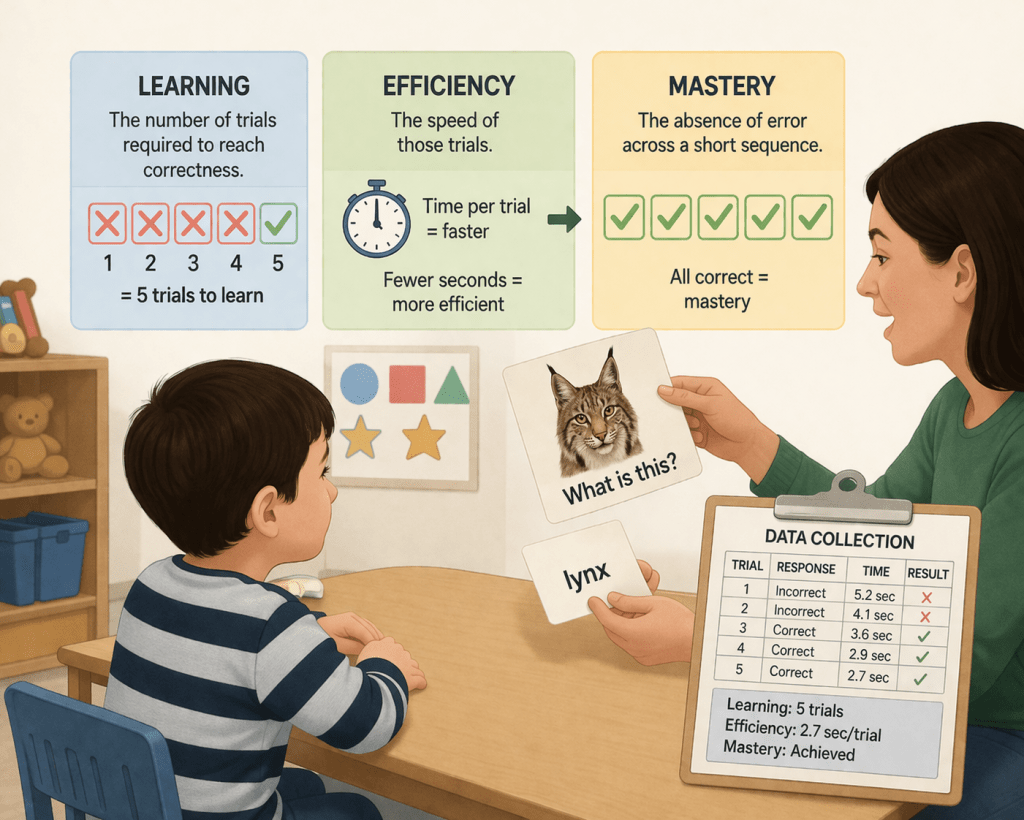
The child is represented through counts, speed, and error reduction. Learning, efficiency, and mastery are defined by measurable outputs rather than by understanding.
Peysin positions his findings as useful for designing more effective educational interventions, but the scope of what is being claimed exceeds what the study actually measures. The outcomes labeled as “learning” consist of children producing correct verbal responses to isolated stimuli, such as naming pictured objects, under tightly controlled conditions. These responses are achieved through repeated prompting and reinforcement until accuracy is reached, yet the study does not examine whether those responses function as language outside the instructional format or contribute to meaningful communication. The ethical concern is how this “research” may be used to support claims of medical necessity. It is unclear why such work should be funded by Medicaid and taxpayer dollars when it is not framed as medical research.
Peysin completed this study as part of a doctoral requirement in Applied Behavior Analysis, a field whose procedures are designed to be implemented by trained technicians under supervision. Peysin’s dissertation is not independent of the system it evaluates. It is produced within a training pipeline that requires demonstration of the same procedural outcomes it seeks to validate. To earn the degree, the researcher must show that the system generates measurable, reliable responses. The study reproduces the conditions under which ABA evaluates and sustains its procedures. What is presented as evaluation is also credentialing.
The system defines learning as correct responding, trains practitioners to produce it, and evaluates success using those same criteria. Spontaneous language, uneven progress, refusal, distraction, and alternative engagement were not recorded unless they interrupted instruction. They were treated as deviations to be corrected rather than as information about the child. It did not determine whether those outcomes were meaningful. Efficiency and mastery describe how the system operates. A system can be efficient and still miss the point. For very young autistic children, the stakes of that distinction are not theoretical; they are lived every day.

Measured outcomes align within the system, but may not align with what families and autistic individuals value.

Leave a comment